Semantic Code Completion
- Ivaylo Fiziev
- Feb 16, 2023
- 3 min read


You've probably seen this kind of code assistance in many products. We take it for granted but if you try to do something like this yourself you'll quickly feel discouraged. Why? Because it is a complex, non trivial code that is considered "black magic" by most of the developers out there.
The problem of recognizing what the user is trying to type and provide meaningful suggestions in a particular context seems impossible at first. When I started working on this I had only this question in my head: How on earth am I going to do this?
I struggled for quite long with this dilemma. There is not a standard solution available today. After a lot of searching and reading it became clear that the solution should be done per language instead. So I had to come up with a solution for SCL. This made things somewhat easier since I had to focus only on one specific syntax. And still … How to approach this?
Our SCL implementation is based on ANTLR4 - a powerful parser generator. The solution should be somehow based on it.
ANTLR generates lexer/parser code in your target language (in our case C++) based on the so-called language grammar. The language grammar is a text file describing your language syntax (in our case SCL). In essence ANTLR provides a standard grammar for describing your language grammar … Wait what? Yes. This is what it is. And it is quite powerful. ANTLR uses the grammar you define in the text file to create a state machine.
They call it ATN (Augmented Transition Network). Believe it or not this happen to be the backbone of code completion.
To explain this better I'll provide a real world example - the IF statement in SCL:

When defining the language grammar we use two type of rules:
a) lexer rules (red) - they define the tokens (keywords, operators, literals, comments) of the language. When parsing the code, the input stream is being split into tokens defined by the lexer rules.
b) parser rules (blue) - they define language constructs (programs, statements, expressions etc.) based on the lexer rules. Each one of these is a separate parser rule defined in the grammar file.
From this definition ANTLR generates a state machine like this:
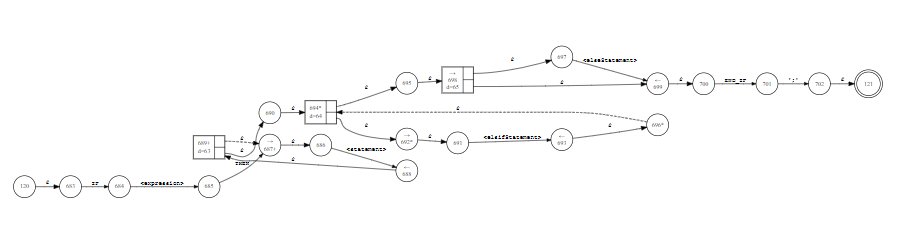
In essence this is the state machine that the parser uses to ensure correctness of the code. Each circle represents a well known state. The arrows between the estates are called transitions. Some transitions do not consume any input (epsilon transitions) and other do require some input (label transitions). Rule transitions are used when the input should match another parser rule. There can be multiple transitions from one state to the next. Now if the parser cannot move from one state to the next because no transition exists that satisfies the user input then a syntax error is reported.
Based on the transitions the parser can predict the possible tokens that can appear after a given state. Halt on for a moment! What? Isn't this what code completion is all about?
Predicting the upcoming tokens? Yes. This is exactly what it is. So I needed a way to traverse the ATN and find possible transitions at the cursor position... Let me say that again: I need a list of possible tokens that can follow the one at the cursor position.
e.g. something like this:

Wait a minute. The tokens are defined in the language grammar. What I need here is a list of names (in this case variable names) not defined in the grammar. Now what? Well the names a identifiers. The grammar defines what an identifier is. So what I need is a way to resolve possible identifiers after I realize that I need them at the cursor position. And this is what semantic code completion is all about. To implement this however I need not only the list of upcoming tokens but also a way to identify the parser rule that has been matched at the cursor position... Honestly it wasn't easy to twist my mind around this idea...
Luckily with semantic code completion we will always be looking for identifiers after the cursor position. So what we really need is a way to identify the parser rules. And this is what I did eventually - a backtracking ATN traversal function that accumulates the parser rules until a token is found beyond the cursor position. Then it tries to resolve the candidates. The candidates are being resolved differently based on the parser rule that we are currently in.
It was an eye opening moment for me when I could get this working. Of course it was not all perfect but still a great achievement.
Cheers!



Comments